Migration system for Zoe microservices
This is the title of my Bachelor Thesis, which focused on the development of an addition to the Zoe virtual assistant that enabled live migration of Zoe agents during runtime. Rather than modifying the original system or employing solutions such as virtualization or containers, which may have been a little too overkill for this scenario, I designed and implemented a software-based solution with the help of my supervisor, Professor David Expósito from UC3M.
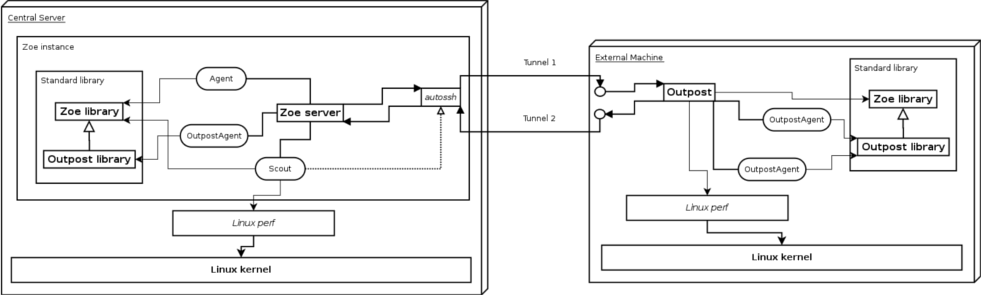
I took extra care to make it completely compatible with the original Zoe architecture without modifying any internal component (don't really want to force anyone to use the system). This was achieved by adding a new element to the library (for the time being, only Python is implemented), which can be found here. Basically, it includes four additional methods to manage data migration and some additional messages for the process. Given that it extends the original library, it works as a regular agent in any case, plus only some lines need to be modified in order to convert a normal agent to a migration-capable one.
These outpost agents are migrated to an outpost, which is a small server being executed in a remote machine that will relay messages to and from migrated agents through a tunnel (established through SSH). In addition, and in order to do more interesting things with the system, the outpost periodically obtains the million instructions per second (MIPS) of each of the agents by means of the Linux perf tool. This information is relayed to the central system and can be used in load balancing algorithms!
Of course, this system would not be complete without a component that managed the outposts and agent migrations. This component is called Scout and is simply a normal Zoe agent. Basically, it opens the tunnels, launches the outposts, stores and delivers agent information when migrating and copies agent files across machines. However, it is also in charge of sending periodic messages to outposts (update users information, gather MIPS, etc.), obtaining MIPS for (outpost) agents in the central server and performing load balancing. For the time being, it has two algorithms based on machine load and user specified priority, but more of these can be easily implemented without modifying the core of the Scout.
An overview of the system can be seen below:
Now for the magic: data migration. Honestly, it is very difficult to design something to migrate data that can be applied in every programming language, so instead of that, I created a simple protocol (on top of the Zoe protocol) where special messages trigger language-specific functionalities. For Python, data is (de)serialized using the pickle module and transmitted in a message using the Base 64 alphabet. Of course, It is impossible to make assumptions on every possible use case, so agent developers have to specify the data they want to migrate and how the agent has to behave before/after a migration occurs.
The resulting system is far from perfect, but I'm very happy with how it turned out. If you want to know more about it you can check both the code (with some parts released under MIT license and others under GPLv3 license) and the document, which is much more detailed than this introductory post:
- Code: https://github.com/rmed/bachelor_thesis
- Document: https://archive.rmedgar.com/academic/migration_system_zoe.pdf
PS: the evaluation of the load balancing algorithms was quite interesting, especially in the overloaded scenarios.